
Secondary Data
Last Updated:
What is secondary data?

Why study secondary data?
Digital images are untapped sources of ecological discovery. Through secondary data, we can study any physical, observational event to better understand a species’ ecology and biology. This information has already been used, for example, to support taxonomic classifications (Mesaglio et al., 2025), indicate changing climate conditions (Steinke et al., 2025), and reveal new species interactions (Zamani et al., 2024), and host associations (Zhang et al., 2022). In addition to these direct uses of secondary data for ecological discovery, there remains much unexplored potential for indirect applications of secondary data, which I aim to demonstrate through my Master’s thesis work. Moreover, secondary data is applicable to all digital images, including pictures uploaded to participatory scientist platforms, digitized museum records, and images collected from insect and wildlife camera traps (e.g., Steinke et al., 2025).
Who can use secondary data?
Secondary data provides exciting opportunities for both participatory scientists and academics. Because secondary data must be manually extracted from images (see below for info on automated data extraction), ecological discovery from secondary data can be somewhat situational or coincidental in the traditional sense of “discovery,” such as finding an image of a species exhibiting a new behavior or interaction. On the other hand, discoveries can be intentional in cases where images are being intentionally searched for secondary data and then statistical analyses performed on the data reveal some “discovery.” Both examples indicate that ecological discovery from secondary data can be made by anyone!
How do we get secondary data?
Currently, extracting secondary data from images is a manual effort, where you must look at the image and determine whether it contains the secondary data of interest. Much of the current research on secondary data has relied on manual data extraction because secondary data can take many forms (e.g., habitat, morphology, behavior). On iNaturalist, it is possible to add “annotations” to images observations, but many observations lack annotations. Additionally, because secondary data comes in many forms, it would be quite difficult to annotate every observation with all the secondary data it contains.
Through recent advancements in computer vision, researchers are applying deep learning models to automate the extraction of secondary data. I want to emphasize that “automate” does not necessarily replace humans in the process of retrieving secondary data from images. Streamline would be a better term to describe how AI models are facilitating the process of secondary data extraction because humans are still heavily involved in how the data is retrieved and analyzed.
A classic approach involves fine-tuning general foundation image classification models. In Alyetama et al. (2025), the authors fine-tuned a YOLOv8 image classification model to classify mammal tracks and signs. However, the approach applied in Alyetama et al. is restricted to the particular applications on which the model was trained; in this case, you can only use this model for distinguishing mammal tracks and signs, so you would need to create more models for other types of secondary data.
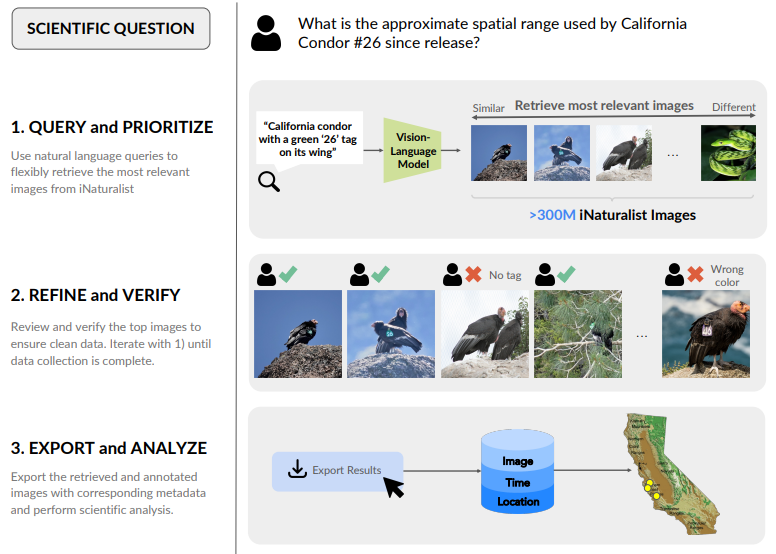
Figure 2 from Vendrow, Chae, Kurinchi-Vendhan et al., 2025 demonstrating the INQUIRE-Search framework (reproduced under CC BY-NC-SA 4.0).
So, we have the existing technology that is capable of automating, or streamlining, the extraction of secondary data. And we also have a framework for the secondary data retrieval process. However, there is a lack of readily-available tools for anyone to use. Vendrow, Chae, Kurinchi-Vendhan et al. (2025) do have a web-hosted version of INQUIRE-Search; unfortunately, this interface has never worked on my computers (perhaps it will for yours?). I have preliminary explored ways to develop an accessible interface for streamlining the exploration of secondary data (see below for more information about the Secondary Data Explorer). I am interested in improving accessibility of tools related to secondary data for researchers and participatory scientists alike.
Table of Contents
See below the topics below for more information, explanation, resources, and tools related to secondary data!
- My work on secondary data
- Others’ work on secondary data
- Secondary data in wildlife & insect camera trap images
- Automated extraction of secondary data
- Related topics
My Master’s thesis reserach
TBD
The Secondary Data Explorer
The Secondary Data Explorer emerged from an interest to:
- automate secondary data extraction,
- showcase how awesome vibe coding is, and
- provide accessible tools for both researchers and participatory scientists.
…TBD
Vibe Coding
TBD
 This work is licensed under a CC BY-NC-ND 4.0 International License.
This work is licensed under a CC BY-NC-ND 4.0 International License. © 2026 Karina M. Torres. All rights reserved.
If referencing any preliminary findings or ideas, please cite as:
Torres, K. M., "Secondary Data," Personal Website, May 2026.